
亚马逊宣布开源深度学习工具,“Open”AI或成主流?
2016年5月11日下午,亚马逊在GitHub网站将其深度学习和机器学习工具DSSTNE开源。
【编者按】本文由新智元编译,来源:GitHub、Hacker News,编译:胡祥杰
亚马逊也被吹上“flow”的风口:继Facebook昨天公开其深度学习训练平台FBLearner Flow细节,亚马逊突然宣布开源其深度学习和机器学习工具DSSTNE,并表示与相比其他深度学习工具,DSSTNE尤其擅于训练稀疏数据。近年来,谷歌,FB和OpenAI先后搭建平台,亚马逊也宣布工具开源,人工智能系统未来开源趋势已成,国内公司何时跟上国际潮流?

2016年5月11日下午,亚马逊在GitHub网站将其深度学习和机器学习工具DSSTNE开源(译注:DSSTNE与英语“destiny”谐音)。亚马逊方面称,与其他开源工具相比,DSSTNE尤其擅长训练稀疏数据。新智元第一时间搜集信息,并获得内部核心开发人员对这款工具的详解。
向来在开源上不那么积极的亚马逊有了新动作。难道最近在科技巨头间掀起了一股“开源”的浪潮?我们能否期待接下来苹果也会把它家的深度学习来个开源?!!玩笑说到这里,下面我们就一起来看看,亚马逊这个DSSTNE深度学习工具到底有什么用处。
DSSTNE是什么?
根据GitHub网站消息,DSSTNE是英文“Deep Scalable Sparse Tensor Network Engine”的简写,即“深度可伸缩的稀疏张量网络工具”。亚马逊相关研究团队对DSSTNE的描述是 “一个使用GPU训练和部署深度神经网络的开源工具”。
亚马逊的工程师最初创建DSSTNE是用于解决在亚马逊平台上需要处理的深度学习难题,建立的目标是解决现实中深度学习应用的产品部署问题,在试验灵活性以外,还强调速度和规模。团队希望把深度学习的潜力从语音、语言理解和物体识别领域扩展到搜索和推荐等其他领域,激发更多创意。
每一天,有上亿人在亚马逊购物。亚马逊希望DSSTNE能帮助消费者从众多的商品中发现想找的东西。而想要做到好的推荐,就需要神经网络。即便是简单的3层自动编码器,加上一个有上亿节点的输入层(每一个节点代表一件商品),以及一个包含1000节点的隐藏网络,还有一个能反映输入层的输出层,所需要学习的参数就可以达到10亿以上。利用目前的硬件,这是很难实现的。即使把神经网络的大小局限在单一商品目录和身处美国的用户,也几乎要触及当下GPU的能力上限了。
举例来说,一个3层的自动编码加权矩阵,加上输入时的800万个界定,以及输出层和隐藏层的256个节点,运行一次简单的计算就需要消耗8G的内存。使用开放资源软件以及上千万用户的消费数据来训练这样的网络,用市场上最快的GPU也得花上数周才能得到结果。亚马逊意识到,如果不能写出软件,然后在多个GPU中分配这些计算的话,他们是不会有大的进步的。
DSSTNE有一系列的特征:
多GPU伸缩:训练和预测扩展到使用多GPUs,在每一层平行模型拓展计算和存储。
多层:模式平行伸缩,让更大型的网络成为可能。
稀疏数据:在稀疏数据集中,DSSTNE经过了优化,可以有更快速的表现。特殊的GPU核心程序在GPU中运行稀疏计算。
DSSTNE与其他深度学习工具不同之处
在一些数据稀疏(几乎所有的数值都为零)的任务中,DSSTNE的表现要远优于当下的一些开放资源深度学习工具。
DSSTNE是从无到有的一个工具,用于训练数据稀疏条件下的模型,其他的数工具,比如Caffe,Tensorflow,Theano和Torch都拥有大型的功能集以及网络支持。DSSTNE在气质上跟Caffe很像,强调产品应用的表现。在涉及稀疏数据的问题中,DSSTNE比其他仍和深度学习工具都要快(2.1x compared to Tensorflow in 1 g2.8xlarge),其中就包括推荐难题和许多自然语言理解(NLU)任务。单个服务器内,多GPU运行的情况,DSSTNE的表现也比其他的数据库表现要好。DSSTNE能够在所有可用的GPU中自动分配计算任务,加速所有的计算过程,并能建立更大的模型。从实际上来看,这意味着它能建立起推荐系统,把上千万种商品囊括到模型中,而不是上万种,或者能处理包含大量词汇的自然语言理解任务。对于这种等级的难题,其他的工具可能会需要转化到CPU来计算稀疏数据,这会将效果降低一级。另外,DSSTNE的网络定义语言会比Caffe的简单得多,只需要33行代码来表示通用的AlexNet图像识别模型,而Caffe语言要求超过300行代码。
但是,DSSTNE还不支持图像识别所需要的卷积层,在一些自然语言理解和语音识别任务所需要的复发层中,支持也很有限。
该怎么用DSSTNE训练神经网络模型?
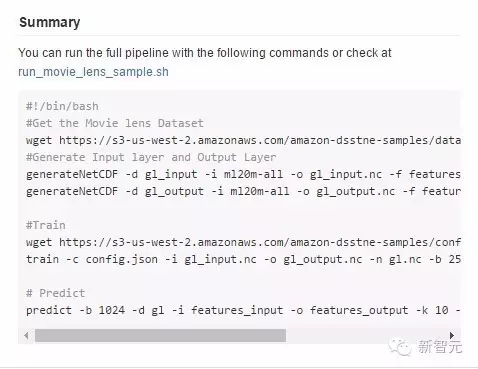
亚马逊在GitHub网站上给出了使用DSSTNE训练神经网络模型的实例,包含3个基本步骤:转换数据、训练、预测。
1. 转换数据:
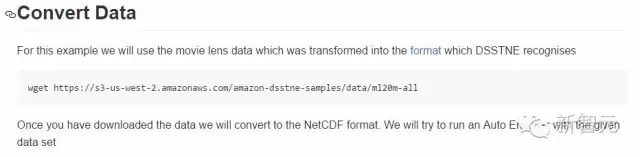
下载数据后,把数据转换到NetCDF格式。然后在指定数据集中尝试运行一个自动编码器。
1.1 生成输入数据集:
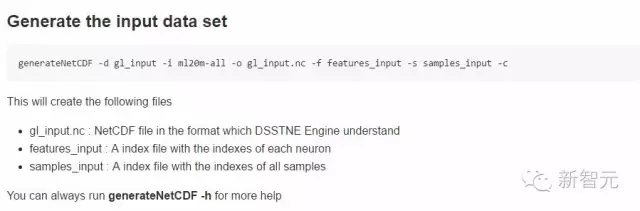
1.2 生成输出数据:

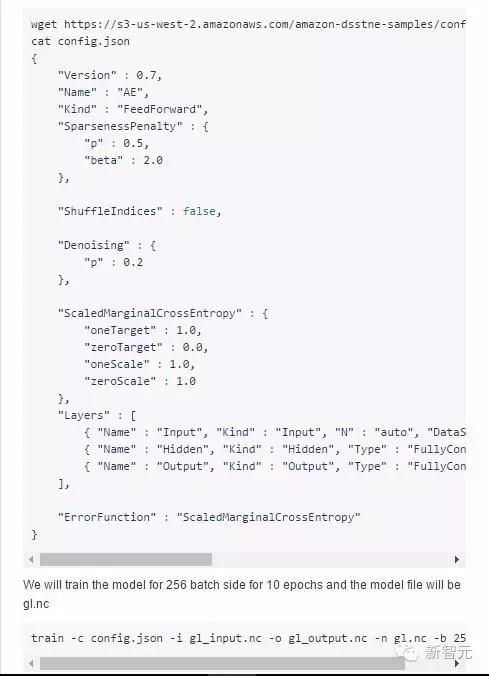
2. 训练:3层神经网络的隐藏层有128个节点
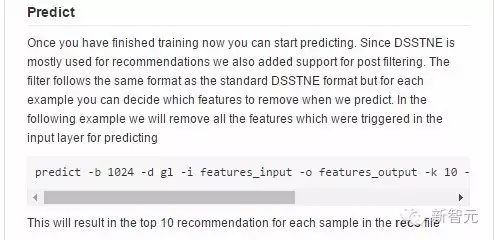
3. 预测:
总结
内部人员神吐槽
亚马逊开源DSSTNE的消息发布后不久,一位前DSSTNE核心开发成员就在hackernews网站上透露,DSSTNE创建于2年前,专用于在亚马逊商品目录中进行产品推荐。他表示:当时Tensorflow还没诞生,只有Theano和Torch;DSSTNE通过稀疏数据和多GPU跨神经网络进行优化,跟Theano和Torch都不一样;现在DSSENE还不支持Alex、VGG或者GoogleNet等,但是如果有需要,只用500行代码就能实现。
那位前DSSTNE核心开发员还透露,DSSTNE现在还不明确支持RNN,但它支持分享加权。而虽然CuDNN 5使用几百行代码就能支持LSTM,但他认为CuDNN中的LSTM是一个黑盒子(Black Box),所以不能扩展到多重GPU。
那位程序员还表示,亚马逊并不完美,但这家公司让他们从头开始搭建了这一平台,然后现在对外开源。据这位不愿意透露姓名的程序员表示,加入亚马逊之前,谷歌把他从Nvidia挖去(这是他难以拒绝的几个offer之一),但2011年却把他分配到搜索团队,不让其再涉及GPU的工作,完全没有考虑到他是Nvidia CUDA团队的创始成员之一,因此他认为谷歌完全没有认识到GPU的作用。在谷歌他没有待太久,如果他还留在亚马逊,他认为亚马逊会让他从事开源编码相关工作。
这位选择匿名的程序员表示,在DSSTNE这个项目中自己是唯一的GPU编码员,在接受了又一份难以拒绝的offer后,他在4个月前离开了亚马逊。在他离开时,DSSENE的工作人员不到10人,并且其中大部分都已经到别处进行深度学习引擎开发去了。
在hackernews网站写下这些文字的时候,那位不愿意透露姓名的程序员表示,他正在等飞机,在接下来的几天中将持续跟进这件事。最后,他写了一点剧透:
DSSTNE的每一个GPU,处理的都是近乎完美伸缩的,具有1000个以上隐藏单元的隐藏层以及高效的自由稀疏输入层,因为激活和加权梯度计算有特定的稀疏核心;此外,虽然基于JavaScript轻量级的数据交换格式(JavaScript Object Notiation)在2014年获得认可,但DSSTNE需要一个类似TensorFlow图像输入才能达到100%的兼容。
消息来源:
1、https://github.com/amznlabs/amazon-dsstne
2、https://news.ycombinator.com/item?id=11671787
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 亚马逊
人工智能
亚马逊
人工智能